
Глава 12. Реализация файловой системы
Предыдущая глава | Программа курса | Следующая глава
12.1 Интерфейс файловой системы.
Как уже говорилось, файловая система должна организовать эффективную работу с данными, хранящимися во внешней памяти и предоставить пользователю возможности для запоминания и выборки данных в нем.
Для организации хранения информации на диске пользователь вначале обычно выполняет его форматирование, выделяя на нем место для структур данных, которые описывают состояние файловой системы в целом. Затем пользователь создает нужную ему структуру каталогов (или директорий), которые по существу являются списками вложенных каталогов и собственно файлов. И, наконец, заполняет дисковое пространство файлами, приписывая их тому или иному каталогу. Таким образом, ОС должна предоставить в распоряжение пользователя совокупность сервисов традиционно реализованных через системные вызовы, которые обеспечивают:
создание файловой системы на диске
необходимые операции для работы с каталогами
необходимые операции для работы с файлами
Кроме того, файловые службы могут решать проблемы проверки и сохранения целостности файловой системы, проблемы повышения производительности и ряд других.
Прежде чем приступить к описанию работы отдельных файловых операций, необходимо рассмотреть ключевые алгоритмы и структуры данных, которые обеспечивают функционирование файловой системы.
12.2 Общая структура файловой системы
Система хранения данных на дисках может быть структурирована следующим образом (см. рис. 12.1).
Нижний уровень - оборудование. Это в первую очередь, магнитные диски с подвижными головками - основные устройства внешней памяти, представляющие собой пакеты магнитных пластин (поверхностей), между которыми на одном рычаге двигается пакет магнитных головок. Шаг движения пакета головок является дискретным и каждому положению пакета головок логически соответствует цилиндр магнитного диска. Цилиндры делятся на дорожки (треки), а каждая дорожка размечается на одно и то же количество блоков (секторов), таким образом, что в каждый блок можно записать по максимуму одно и то же число байтов. Следовательно, для произведения обмена с магнитным диском на уровне аппаратуры нужно указать номер цилиндра, номер поверхности, номер блока на соответствующей дорожке и число байтов, которое нужно записать или прочитать от начала этого блока. Таким образом, диски могут быть разбиты на блоки фиксированного размера, и можно непосредственно получить доступ к любому блоку (организовать прямой доступ к файлам).
Непосредственно с устройствами (дисками) взаимодействует часть ОС, называемая система ввода-вывода (см. соответствующую главу). Система ввода-вывода (она состоит из драйверов устройств и обработчиков прерываний для передачи информации между памятью и дисковой системой) предоставляет в распоряжение более высокоуровневого компонента ОС - файловой системы используемое дисковое пространство в виде непрерывной последовательности блоков фиксированного размера. Система ввода-вывода имеет дело с физическими блоками диска, которые характеризуются адресом, например, диск 2, цилиндр 75, сектор 11. Файловая система имеет дело с логическими блоками, каждый из которых имеет номер (от 0 или 1 до N). Размер этих логических блоков файла совпадает или кратен размеру физического блока диска и может быть задан равным размеру страницы виртуальной памяти, поддерживаемой аппаратурой компьютера совместно с операционной системой.
В структуре системы управления файлами можно выделить базисную подсистему, которая отвечает за выделение дискового пространства конкретным файлам, и более высокоуровневую логическую подсистему, которая использует структуру дерева директорий для предоставления модулю базисной подсистемы необходимой ей информации исходя из символического имени файла. Она также ответственна за авторизацию доступа к файлам (см. главу Безопасность ОС).
Рис. 12.1 Блок схема файловой системы
В современных ОС далее принято разбивать диски на логические диски (это также низкоуровневая операция), иногда называемые разделами (partitions). Бывает, что наоборот объединяют несколько физических дисков в один логический диск (например, как это можно сделать в ОС Windows NT). На каждом разделе можно иметь свою независимую файловую систему. Поэтому в дальнейшем изложении мы будем игнорировать проблему физического выделения пространства для файлов и считать, что каждый раздел представляет собой отдельный (виртуальный) диск. Собственно диск содержит иерархическую древовидную структуру, состоящую из набора файлов, каждый из которых является хранилищем данных пользователя, и каталогов или директорий (то есть файлов, которые содержат перечень других файлов, входящих в состав каталога), которые необходимы для хранения информации о файлах системы.
Стандартный запрос на открытие (open) или создание (creat) файла поступает от прикладной программы к логической подсистеме. Логическая подсистема, используя структуру директорий, проверяет права доступа и вызывает базовую подсистему для получения доступа к блокам файла. После этого файл считается открытым, содержится в таблице открытых файлов, прикладная программа получает в свое распоряжение дескриптор (или handle в системах Microsoft) этого файла. Дескриптор файла является ссылкой на файл в таблице открытых файлов и используется в запросах прикладной программы на чтение-запись из этого файла. Запись в таблице открытых файлов указывает через систему аллокации блоков диска на блоки данного файла. Если к моменту открытия файл уже используется другим процессом, то есть содержится в таблице открытых файлов, то, после проверки прав доступа к файлу может быть организован совместный доступ. При этом новому процессу также возвращается дескриптор - ссылка на файл в таблице открытых файлов. Далее в тексте подробно проанализирована работа наиболее важных системных вызовов.
12.3 Структура файловой системы на диске.
Прежде чем рассмотреть структуру данных файловой системы на диске необходимо рассмотреть алгоритмы выделения дискового пространства и способы учета свободной и занятой дисковой памяти.
12.3.1 Методы выделения дискового пространства
Ключевой вопрос реализации способ связывания файлов с блоками диска. В ОС используется несколько методов выделения файлу дискового пространства. Для каждого метода сведения о локализации блоков данных файла можно извлечь из записи в директории, соответствующей символьному имени файла.
Выделение непрерывной последовательностью блоков
Простейший способ - хранить каждый файл, как непрерывную последовательность блоков диска. При непрерывном расположении файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока b, занимает затем блоки b+1, b+2, ... b+n-1.
Эта схема имеет два преимущества. Во-первых, ее легко реализовать, т.к. выяснение местонахождения файла сводится к вопросу, где находится первый блок. Во-вторых, она обеспечивает хорошую производительность, т.к. целый файл может быть считан за одну дисковую операцию.
Непрерывное выделение используется в ОС IBM/CMS, в ОС RSX-11 (для выполняемых файлов) и в ряде других.
Основная проблема, вследствие чего этот способ мало распространен - трудно найти место для нового файла. В процессе эксплуатации диск представляет собой некоторую совокупность свободных и занятых фрагментов. Проблема непрерывного расположения может рассматриваться как частный случай более общей проблемы выделения n блоков из списка свободных дыр. Наиболее распространенные стратегии решения этой проблемы - first fit, best fit и worst fit (ср. с проблемой выделения памяти). Таким образом, метод страдает от внешней фрагментации, в зависимости от размера диска и среднего размера файла, в большей или меньшей степени.
Кроме того, непрерывное распределение внешней памяти не применимо до тех пор, пока не известен максимальный размер файла. Иногда размер выходного файла оценить легко (при копировании). Чаще, однако, это трудно сделать. Если места не хватило, то пользовательская программа может быть приостановлена, предполагая выделение дополнительного места для файла при последующем рестарте. Некоторые ОС используют модифицированный вариант непрерывного выделения основные блоки файла + резервные блоки. Однако с выделением блоков из резерва возникают те же проблемы, так как возникает задача выделения непрерывной последовательности блоков диска теперь уже из совокупности резервных блоков.
Связный список
Метод распределения блоков в виде связного списка решает основную проблему непрерывного выделения, то есть устраняет внешнюю фрагментацию. Каждый файл - связный список блоков диска. Запись в директории содержит указатель на первый и последний блоки файла. Каждый блок содержит указатель на следующий блок.

Рис. 12.2 Хранение файла в виде связного списка дисковых блоков
Внешняя фрагментация для данного метода отсутствует. Любой свободный блок может быть использован для удовлетворения запроса. Заметим, что нет необходимости декларировать размер файла в момент создания. Файл может неограниченно расти.
Связное выделение имеет, однако, несколько существенных недостатков.
Во-первых, при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i-1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени.
Прямым следствием этого является низкая надежность. Наличие дефектного блока в списке приводит к потере информации в остаточной части файла и, потенциально, к потере дискового пространства отведенного под этот файл.
Наконец, для указателя на следующий блок внутри блока нужно выделить место. Емкость блока, традиционно являющаяся степенью двойки (многие программы читают и пишут блоками по степеням двойки), таким образом, перестает быть степенью двойки, т.к. указатель отбирает несколько байтов.
Поэтому метод связного списка обычно не используется в чистом виде.
Связный список с использованием индекса
Недостатки предыдущего способа могут быть устранены путем изъятия указателя из каждого дискового блока и помещения его в индексную таблицу в памяти, которая называется FAT (file allocation table). Этой схемы придерживаются многие ОС (MS-DOS, OS/2, MS Windows и др.)

Рис. 12.3. Метод связного списка, с использованием таблицы в оперативной памяти
По-прежнему, существенно, что запись в директории содержит только ссылку на первый блок и т.о. можно локализовать файл независимо от его размера.
Минусом этой схемы может быть необходимость поддержки в памяти этой довольно большой таблицы.
Индексные узлы
Четвертый и последний метод выяснения принадлежности блока
к файлу - связать с каждым файлом маленькую таблицу,
![]() называемую
индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков
файла (см. рис 12.4).
называемую
индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков
файла (см. рис 12.4).
Каждый файл имеет свой собственный индексный блок, который содержит адреса блоков данных. Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения.
Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации.
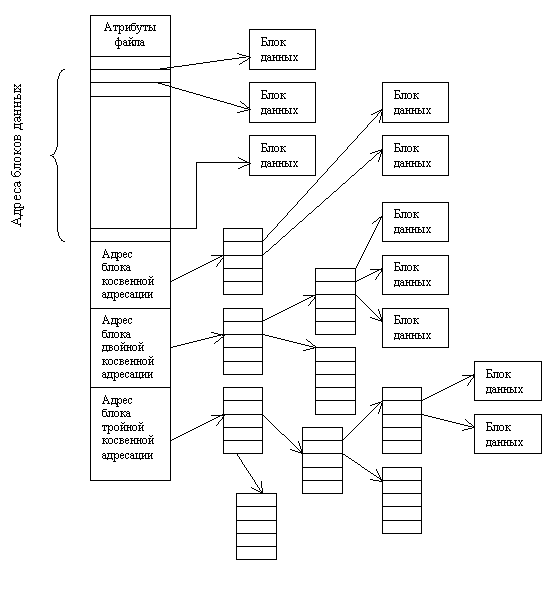
Рис. 12.4 Структура индексного узла
Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, т.о. для маленьких файлов индексный узел хранит всю необходимую информацию, которая копируется с диска в память, в момент открытия файла. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Этот блок содержит адреса дополнительных блоков диска. Если этого недостаточно используется блок двойной косвенной адресации, который содержит адреса блоков косвенной адресации. Если и этого недостаточно используют блок тройной косвенной адресации.
Эту схему использует Unix (а также файловые системы HPFS, NTFS и др.). Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла, поддерживать работу с файлами, размер которых может меняться от нескольких байт до нескольких гигабайт. Существенно, что для маленьких файлов используется только прямая адресация, обеспечивающая максимальную производительность.
12.3.2 Управление свободным и занятым дисковым пространством.
В современных ОС используется несколько способов учета используемого места на диске. Рассмотрим наиболее распространенные.
Учет при помощи организации битового вектора.
Часто список свободных блоков диска реализован в виде битового вектора (bit map или bit vector). Каждый блок представлен одним битом, принимающим значение 0 или 1, в зависимости от того занят он или свободен. Например, 00111100111100011000001 ....
Главное преимущество этого подхода - он относительно прост и эффективен при нахождении первого свободного блока, или n последовательных блоков на диске. Многие компьютеры имеют инструкции манипулирования битами, которые могут быть использованы для этой цели. Например, компьютеры семейств Intel и Motorola имеют инструкции, которые при помощи которых можно легко локализовать первый единичный бита в слове.
Описываемый метод учета свободных блоков используется в Apple Macintosh.
К сожалению, этот метод эффективен, только если битовый вектор помещается в памяти целиком, что возможно только для относительно небольших дисков. Например, диск размером 1.3 Гб с блоками по 512 байт нуждается в таблице размером 332К для управления свободными блоками.
Учет при помощи организации связного списка.
Эта схема не всегда эффективна. Для трассирования списка нужно сделать много обращений к диску. Однако к счастью нам необходим, как правило, только первый свободный блок.
Иногда прибегают к модификации подхода связного списка, организуя хранение адресов n свободных блоков в первом свободном блоке. Первые n-1 этих блоков действительно используются. Последний блок содержит адреса других n блоков. И т.д.
Размер логического блока играет важную роль. В некоторых системах (Unix) он может быть задан при форматировании. Небольшой размер блока будет приводить к тому, что каждый файл будет содержать много блоков. Чтение блока осуществляется с задержками на поиск и вращение, т.о. файл из многих блоков будет читаться медленно. Большие блоки обеспечивают более высокую скорость обмена с диском, но вследствие внутренней фрагментации (каждый файл занимает целое число блоков и в среднем половина последнего блока пропадает) снижается процент полезного дискового пространства.
В системах со страничной организацией памяти имеется сходная проблема с размером страницы.
Проведенные исследования показали, что большинство файлов имеет небольшой размер (в Unix приблизительно 85% файлов имеют размер менее 8 Кбайт и 48% - менее 1Кбайта).

Рис. 12.5. Определение оптимального размера блока.
На рис. 12.5 изображены две кривые: одна убывающая показывает степень утилизации диска (в процентах) с возрастанием размера блока, а вторая возрастающая скорость считывания информации. Они пересекаются в районе 3К. Обычный компромисс выбор блока размером 512 б, 1К, 2К.
12.3.4 Структура файловой системы на диске
Рассмотрение методов работы с дисковым пространством дает общее представление о совокупности служебных данных, необходимых для описания файловой системы. Структуры данных типовой файловой системы, например Unix, на одном из разделов диска, таким образом, может состоять из 4-х основных частей:

Рис. 12.6 Примерная структура файловой системы на диске.
В начале раздела находится суперблок, содержащий общее описание файловой системы, например:
Описанные структуры данных создаются на диске в результате его форматирования (например, утилитами format, makefs и др.). Их наличие позволяет обращаться к данным на диске как к файловой системе, а не как к обычной последовательности блоков.
В файловых системах современных ОС для повышения устойчивости поддерживается несколько копий суперблока. В некоторых версиях Unix суперблок включал также и структуры данных, управляющие распределением дискового пространства, в результате чего суперблок непрерывно подвергался модификации, что снижало надежность файловой системы в целом. Выделение структур данных, описывающих дисковое пространство, в отдельную часть является более правильным решением.
Массив индексных узлов (ilist) содержит список индексов, соответствующих файлам данной файловой системы. Размер массива индексных узлов определяется администратором при установке системы. Максимальное число файлов, которые могут быть созданы в файловой системе, определяется числом доступных индексных узлов.
В блоках данных хранятся реальные данные файлов. Размер логического блока данных может задаваться при форматировании файловой системы. Заполнение диска содержательной информацией предполагает использование блоков хранения данных для файлов директорий и обычных файлов и имеет следствием модификацию массива индексных узлов и данных, описывающих пространство диска. Отдельно взятый блок данных может принадлежать одному и только одному файлу в файловой системе.
Как уже говорилось, директория или каталог это файл, имеющий определенный тип и хранящий список входящих в него файлов или каталогов. Основная задача файлов-директорий поддержка иерархической древовидной структуры файловой системы. Запись в директории имеет определенный для данной ОС формат, зачастую неизвестный пользователю, поэтому блоки данных файла-директории заполняются не через операции записи, а при помощи специальных системных вызовов (например, создание файла).
Для доступа к файлу ОС использует путь (pathname), сообщенный пользователем. Запись в директории связывает имя файла или имя поддиректории с блоками данных на диске. В зависимости от системы эта ссылка может быть дисковым адресом целого файла (непрерывное расположение), номером первого блока (связанный список), или номером индексного узла. Во всех случаях главная функция системы директорий - трансформировать символьное имя файла в информацию, необходимую, чтобы найти данные.
Отдельная проблема способ хранения атрибутов файла. Иногда их хранят непосредственно в записи в директории. Для системы с индексными узлами можно хранить атрибуты в индексном узле, а не в записи в директории. Как мы увидим позже, этот метод имеет ряд преимуществ при организации совместного доступа к файлам.
Рассмотрим несколько конкретных примеров.
12.4.1 Примеры реализация директорий в некоторых ОС
Директории в ОС CP/M
В ОС CP/M только одна директория.
Каждая запись - строка содержит следующие поля: идентификатор собственника, имя файла, тип файла, поле extent, которое показывает, хватит ли для идентификации файла одной строки или нужны еще, число блоков, номера блоков. То есть адреса всех блоков файла перечислены в записи в директории!
Директории в ОС MS-DOS
В ОС MS-DOS типовая запись в директории имеет вид:

Рис. 12.7 Вариант записи в директории MS-DOS
В ОС MS-DOS, как и в большинстве современных ОС, директории могут содержать поддиректории (специфицируемые битом атрибута), что позволяет конструировать произвольное дерево директорий файловой системы.
Номер первого блока используется в качестве индекса в таблице FAT . Далее по цепочке могут быть найдены остальные блоки.
Структура директории проста. Каждая запись содержит имя файла и номер его индексного узла. Вся остальная информация о файле (тип, размер, времен модификации, владелец и т. д. и номера дисковых блоков) находится в индексном узле.

Рис. 12.8 Вариант записи в директории Unix
Итак, директория - есть файл, имеющий специальный формат, состоящий из записей фиксированной длины, где каждая запись соответствует одному из обычных файлов или директорий, входящих в состав данной директории. Как правило, список файлов в директории оказывается не упорядоченным по именам файлов. Поэтому правильный выбор алгоритма поиска имени файла в директории имеет большое влияние на эффективность и надежность файловых систем.
Линейный поиск
Совокупность записей о файлах в директории является линейным списком символьных имен файлов. Существует несколько стратегий просмотра такого списка. Простейшей из них является линейный поиск. Директория просматривается с самого начала, пока не встретится нужное имя файла. Хотя это наименее эффективный способ поиска, оказывается, что в большинстве случаев он работает с приемлемой производительностью. Например, авторы Unix утверждали, что вполне достаточно линейного поиска. По-видимому, это связано с тем, что на фоне относительно медленного доступа к диску, некоторые задержки, возникающие в процессе сканирования списка несущественны.
Метод прост, но требует временных затрат. Для создания нового файла вначале нужно просканировать директорию на наличие такого же имени. Затем, имя нового файла вставляется в конец директории (если, разумеется, файл с таким же именем в директории не существует, в противном случае нужно информировать пользователя). Для удаления файла нужно также выполнить поиск его имени в списке и пометить запись как неиспользуемую.
Реальный недостаток данного метода - линейный поиск файла. Информация о структуре директории используется часто, и плохая реализация будет замечена пользователями. Можно свести поиск к бинарному, если отсортировать список файлов. Однако это усложнит создание и удаление файлов, так как требуется перемещения большого объема информации.
Хеш таблица
Хеширование (см. например, [13]) - другой способ, который может быть использован для размещения и последующего поиска имени файла в директории. В данном методе имена файлов также хранятся в каталоге в виде линейного списка, но дополнительно используются хеш таблица. Хеш таблица, точнее построенная на ее основе хеш-функция позволяет по имени файла получить указатель на имя файла в списке. Таким образом, можно существенно уменьшить время поиска.
В результате хеширования могут возникать коллизии, то есть ситуации, когда функция хеширования, примененная к разным именам файлов, дает один и тот же результат. Обычно имена таких файлов объединяют в связные списки, предполагая в дальнейшем осуществление в них последовательного поиска нужного имени файла. Выбор хорошего алгоритма хеширования позволяет свести к минимуму число коллизий. Однако всегда есть вероятность неблагоприятного исхода, когда непропорционально большому числу имен файлов функция хеширования ставит в соответствие один и тот же результат. В этом случае преимущество использования этой схемы по сравнению с последовательным поиском практически утрачиваются.
Другие методы поиска
Помимо описанных методов поиска имени файла в директории существуют и другие. В качестве примера можно привести организацию поиска в каталогах файловой системы NTFS при помощи, так называемого B-дерева, которое стало стандартным способом организации индексов в системах баз данных (см., например, [13]).
12.5 Монтирование файловых систем.
Как файл должен быть открыт перед использованием, так и файловая система, хранящаяся на разделе диска, должна быть смонтирована, чтобы стать доступной процессам системы.
Функция mount (монтировать) связывает файловую систему из указанного раздела на диске с существующей иерархией файловых систем, а функция umount (демонтировать) выключает файловую систему из иерархии. Функция mount, таким образом, дает пользователям возможность обращаться к данным в дисковом разделе как к файловой системе, а не как к последовательности дисковых блоков.
Процедура монтирования состоит в следующем. Пользователь (в Unix это суперпользователь) сообщает ОС имя устройства и место в файловой структуре (имя пустого каталога), куда нужно присоединить файловую систему (точка монтирования). Например, в ОС Unix системный вызов mount имеет вид:
mount(special pathname,directory pathname,options);
где special pathname - имя специального файла устройства (в общем случае имя раздела), соответствующего дисковому разделу с монтируемой файловой системой, directory pathname - каталог в существующей иерархии, где будет монтироваться файловая система (другими словами, точка или место монтирования), а options указывает, следует ли монтировать файловую систему "только для чтения" (при этом не будут выполняться такие функции, как write и creat, которые производят запись в файловую систему). Затем ОС проверяет, что устройство содержит действительную файловую систему ожидаемого формата с суперблоком, списком индексов и корневым индексом.
Некоторые ОС осуществляют монтирование автоматически, как только встретят диск в первый раз (жесткие диски на этапе загрузки, гибкие - когда они вставлены в дисковод), ОС ищет файловую систему на устройстве. Если файловая система на устройстве имеется, она монтируется на корневом уровне, при этом к цепочке имен абсолютного имени файла (pathname) добавляется буква раздела.

Рис. 12.9. Две файловые системы до монтирования
Рис. 12.10. Общая файловая система после монтирования
Ядро поддерживает таблицу монтирования с записями о каждой монтированной файловой системе. В каждой записи содержатся информация о вновь смонтированном устройстве, в частности на буфер с его суперблоком и корневой каталог, а также информация о точке монтирования. Для устранения потенциально опасных побочных эффектов число ссылок (см. следующий раздел) на каталог точку монтирования должно быть равно 1. Занесение информации в таблицу монтирования производится немедленно, поскольку монтирующий процесс может приостановиться, следуя процедуре открытия устройства или считывая суперблок файловой системы, а другой процесс тем временем попытался бы смонтировать файловую систему.
Наличие в логической структуре файлового архива точек монтирования требует аккуратной реализации алгоритмов, осуществляющих навигацию по каталогам. Точку монтирования можно пересечь двумя способами: из файловой системы, где производится монтирование, в файловую систему, которая монтируется (в направлении от глобального корня к листу), и в обратном направлении. Алгоритмы поиска файлов должны предусматривать ситуации, в которых очередной компонент пути к файлу является точкой монтирования, когда вместо анализа индексного узла очередной директории приходится осуществлять обработку суперблока монтированной системы.
Иерархическая организация, положенная в основу древовидной структуры файловой системы современных ОС, не предусматривает выражения отношений, в которых потомки связываются более чем с одним предком. Такая негибкость частично устраняется возможностью реализации связывания файлов или организации линков.
12.6.1 Организация связи между каталогом и разделяемым файлом
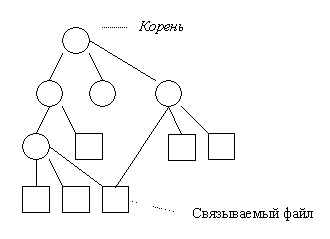
Рис. 12.11 Структура файловой системы с возможностью связывания файла с новым именем.
Ядро позволяет пользователю связывать каталоги, упрощая написание программ, требующих пересечения дерева файловой системы. Часто имеет смысл хранить под разными именами одну и ту же команду (выполняемый файл). Например, выполняемый файл традиционного текстового редактора ОС UNIX vi обычно может вызываться под именами ex, edit, vi, view и vedit файловой системы. Соединение между директорией и разделяемым файлом называется связью или ссылкой (link). Дерево файловой системы превращается в циклический граф.
Это удобно, но создает ряд дополнительных проблем.
![]()
Простейший способ реализовать связывание файла - просто дублировать информацию о нем в обеих директориях. При этом, однако, может возникнуть проблема совместимости, в случае, если владельцы этих директорий попытаются независимо друг от друга изменить содержимое файла. Например, если запись в директории о файле непосредственно содержит адреса дисковых блоков, как в ОС CP/M, копии тех же дисковых адресов должны быть сделаны и в другой директории, куда файл линкуется. Если один из пользователей делает добавление к файлу, новые блоки будут перечислены только у него в директории и не будут видны другому пользователю.
Проблема такого рода может быть решена двумя способами. Первый из них, так называемая жесткая связь. Если блоки данных файла перечислены не в директории, а в небольшой структуре данных (например, в индексном узле), связанной собственно с файлом, то второй пользователь может связаться непосредственно с этой, уже существующей структурой.
Альтернативное решение - создание нового файла, который содержит путь к связываемому файлу. Такой подход называется символической линковкой. При этом в соответствующем каталоге создается элемент, в котором имени связи сопоставляется некоторое имя файла (этот файл даже не обязан существовать к моменту создания символической связи). Для символической связи может создаваться отдельный индексный узел и даже заводиться отдельный блок данных для хранения потенциально длинного имени файла.
Каждый из этих методов имеет свои минусы. В случае жесткой связи возникает необходимость поддержки счетчика ссылок на файл, для корректной реализации операции удаления файла. Например, в Unix, такой счетчик является одним из атрибутов, хранимым в индексном узле. Удаление файла одним из пользователей уменьшает количество ссылок на файл на 1. Реальное удаление файла происходит, когда число ссылок на файл становится равным 0.
В случае символической линковки такая проблема не возникает, т.к. только реальный владелец имеет ссылку на индексный узел файла. Если собственник удаляет файл, то он разрушается, и попытки других пользователей работать с ним кончатся провалом. Удаление символического линка никак не влияет на файл. Проблема организации символической связи потенциальное снижение скорости доступа к файлу. Файл символического линка содержит путь к файлу, содержащий список вложенных директорий, для прохождения по которому необходимо осуществить несколько обращений к диску.
Символический линк имеет то преимущество, что он может использоваться для униформного доступа к файлам удаленных компьютеров, если, например, добавить к пути сетевой адрес удаленной машины.
Циклический граф структура более гибкая, нежели простое дерево, но работа с ней требует большой аккуратности. Одна из серьезных проблем со структурой циклического графа - гарантия того, что не возникает циклов при поиске файла. Поскольку теперь к файлу существует несколько путей, программа поиска файла может найти его на диске несколько раз. Простейшее практическое решение данной проблемы - ограничить число директорий при поиске. Полное устранение циклов довольно трудоемкая процедура, выполняемая специальными утилитами и связанная с многократной трассировкой директорий файловой системы.
12.7 Кооперация процессов при работе с файлами.
Когда различные пользователи работают вместе над проектом, они часто нуждаются в разделении файлов.
Разделяемый файл является разделяемым ресурсом. Как и в случае любого совместно используемого ресурса, процессы должны синхронизировать свой доступ к совместно используемым файлам, каталогам, чтобы избежать тупиковых ситуаций, дискриминации отдельных процессов и снижения производительности системы.
Например, если несколько пользователей одновременно редактируют какой-либо файл и не принято специальных мер, то результат будет непредсказуем и зависит от того, в каком порядке осуществлялись записи в файл. Между двумя операциями read одного процесса, другой процесс может модифицировать данные, что неприемлемо для многих приложений. Простейшее решение данной проблемы предоставить возможность одному из процессов захватить файл, то есть блокировать доступ к разделяемому файлу других процессов на все время, пока файл остается открытым для данного процесса. Однако это было бы не гибко и не соответствовало бы характеру поставленной задачи.
Основные способы средство временный захват процессом файла или записи (части файла между указанными позициями), а также блокировки отдельных структур ядра, отвечающих за работу с файлами. Так, в ОС Unix во время системного вызова, осуществляющего ту или иную операцию с файлом, как правило, происходит блокирование индексного узла, содержащего адреса блоков данных файла. Может показаться, что организация блокировок или запрета более чем одному процессу работать с файлом во время выполнения системного вызова является излишней, так как в подавляющем большинстве случаев выполнение системных вызовов и так не прерывается, то есть ядро работает в условиях невытесняющей многозадачности. Однако в данном случае это не совсем так. Операции чтения и записи занимают продолжительное время и лишь инициируются центральным процессором, а осуществляются по независимым каналам, поэтому установка блокировок на время системного вызова является необходимой гарантией атомарности операций чтения и записи.
Системный вызов, позволяющий установить и проверить блокировки на файл, является неотъемлемым атрибутом современных многопользовательских ОС. В принципе, было бы логично связать синхронизацию доступа к файлу как к единому целому с системным вызовом open (т.е., например, открытие файла в режиме записи или обновления могло бы означать его монопольную блокировку соответствующим процессом, а открытие в режиме чтения - совместную блокировку). Так поступают во многих операционных системах (начиная с ОС Multics). В ОС Unix это не так, что имеет исторические причины.
В первой версии системы Unix, разработанной Томпсоном и Ричи, механизм захвата файла отсутствовал. Применялся очень простой подход к обеспечению параллельного (от нескольких процессов) доступа к файлам: система позволяла любому числу процессов одновременно открывать один и тот же файл в любом режиме (чтения, записи или обновления) и не предпринимала никаких синхронизационных действий. Вся ответственность за корректность совместной обработки файла ложилась на использующие его процессы, и система даже не предоставляла каких-либо особых средств для синхронизации доступа процессов к файлу. Однако впоследствии, для того, чтобы повысить привлекательность системы для коммерческих пользователей, работающих с базами данных, в версию V системы были включены механизмы захвата файла и записи, базирующиеся на системном вызове fcntl.
Допускаются два варианта синхронизации: с ожиданием, когда требование блокировки может привести к откладыванию процесса до того момента, когда это требование может быть удовлетворено, и без ожидания, когда процесс немедленно оповещается об удовлетворении требования блокировки или о невозможности ее удовлетворения в данный момент времени.
Установленные блокировки относятся только к тому процессу, который их установил, и не наследуются процессами-потомками этого процесса. Более того, даже если некоторый процесс пользуется синхронизационными возможностями системного вызова fcntl, другие процессы по-прежнему могут работать с тем файлом без всякой синхронизации. Другими словами, это дело группы процессов, совместно использующих файл, - договориться о способе синхронизации параллельного доступа.
Примеры разрешения коллизий и тупиковых ситуаций
Логика работы системы в сложных ситуациях может проиллюстрировать особенности организации мультидоступа.
Рассмотрим в качестве примера образование потенциального тупика при образовании связи (link) при совместном доступе к файлу [1].
Два процесса, выполняющие одновременно следующие функции:
процесс A: link("a/b/c/d","e/f/g");
процесс B: link("e/f","a/b/c/d/ee");
могут зайти в тупик. Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f". Фраза "в тот же самый момент" означает, что система достигла состояния, при котором каждый процесс получил искомый индекс. Когда же теперь процесс A попытается получить индекс файла "e/f", он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d". Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, нужный процессу A.
Для предотвращения этого классического примера взаимной блокировки в файловой системе принято, чтобы ядро освобождало индекс исходного файла после увеличения значения счетчика связей. Тогда, поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимная блокировка не происходит.
Поводов для нежелательной конкуренции между процессами много, особенно при удалении имен каталогов. Предположим, что один процесс пытается найти данные файла по его полному символическому имени, последовательно проходя компонент за компонентом, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени "a/ b/c/d" и приостанавливается во время получения индексного узла для файла "c". Он может приостановиться при попытке заблокировать индексный узел или при попытке обратиться к дисковому блоку, где этот индексный узел хранится. Если процессу B нужно удалить связь для каталога с именем "c", он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога "c" и его содержимое по этой связи. Позднее, процесс A попытается обратиться к несуществующему индексному узлу, который уже был удален. Алгоритм поиска файла, проверяющий в первую очередь неравенство значения счетчика связей нулю, должен сообщить об ошибке.
Можно привести и другие примеры, которые демонстрируют необходимость аккуратного дизайна файловой системы для ее последующей надежной работы.
12.8 Надежность файловой системы.
Жизнь полна неприятных неожиданностей, а разрушение файловой системы зачастую более опасно, чем разрушение компьютера. Поэтому необходимо предпринимать специальные меры для сохранения структуры файловой системы на диске. Помимо очевидных решений, например, своевременное дублирование информации (backup), файловые системы современных ОС содержат специальные средства для поддержки собственной совместимости.
12.8.1 Целостность файловой системы.
Важный аспект надежной работы файловой системы контроль ее целостности. В результате файловых операций блоки диска могут считываться в память, модифицироваться и затем записываться на диск. Причем, многие файловые операции затрагивают сразу несколько объектов файловой системы. И, если, вследствие непредсказуемого останова системы, на диске будут сохранены изменения только для части этих объектов (нарушена атомарность файловой операции), файловая система на диске может быть оставлена в несовместимом состоянии. В результате могут возникнуть нарушения логики работы с данными, например, появиться потерянные блоки диска, которые не принадлежат ни одному файлу и, в то же время помечены как занятые или наоборот блоки, помеченные, как свободные, но в то же время занятые (на них есть ссылка в индексном узле) или другие нарушения.
В современных ОС предусмотрены меры, которые позволяют свести к минимуму ущерб от порчи файловой системы и, затем, восстановить ее целостность.
Очевидно, что для правильного функционирования файловой системы, значимость отдельных данных неравноценна. Искажение содержимого пользовательских файлов не приводит к серьезным (с точки зрения целостности файловой системы) последствиям, тогда как несоответствия в файлах, содержащих управляющую информацию (директории, индексные узлы, суперблок и т.п.), могут быть катастрофическими. Поэтому должен быть тщательно продуман порядок совершения операций со структурами данных файловой системы.
Рассмотрим, пример создания жесткой связи для файла [32]. Для этого файловой системе необходимо выполнить следующие операции:
1. Создать новую запись в каталоге, указывающую на индексный узел файла
2. Увеличить счетчик связей в индексном узле
Если аварийный останов произошел между 1-й и 2-й операциями, то в каталогах файловой системе будут существовать два имени файла, адресующих индексный узел со значением счетчика связей, равному 1. если теперь будет удалено одно из имен, это приведет к удалению файла как такового. Если же порядок операций изменен и, как прежде, останов произошел между первой и второй операциями, файл будет иметь несуществующую жесткую связь, но существующая запись в каталоге будет правильной. Хотя это тоже является ошибкой, но ее последствия менее серьезны, чем в предыдущем случае.
Другим средством поддержки целостности является способ реализации файловой операции в виде транзакции, примерно как, как это делается в СУБД. Последовательность действий с объектами во время файловой операции протоколируется, и, если произошел останов системы, то, имея в наличии протокол, можно осуществить откат системы назад в исходное целостное состояние, в котором она пребывала до начала операции. Такого рода журналирование реализовано в NTFS.
Если же нарушение все же произошло, то для устранения проблемы несовместимости можно прибегнуть к утилитам (fsck, chkdsk, scandisk и др.), которые проверяют целостность файловой системы. Они могут запускаться после загрузки или после сбоя и осуществляют многократное сканирование разнообразных структур данных файловой системы в поисках противоречий.
Возможны также эвристические проверки. Например, нахождение индексного узла, номер, которого превышает их число на диске или нахождение в пользовательских директориях файлов принадлежащих суперпользователю.
12.8.2 Управление плохими блоками.
Наличие плохих блоков на диске обычное дело. Под плохими блоками обычно понимают блоки диска, для которых вычисленная контрольная сумма считываемых данных не совпадает с хранимой контрольной суммой. Часто появляются в процессе эксплуатации. Иногда они уже имеются при поставке вместе со списком, т.к. очень затруднительно для поставщиков сделать диск полностью свободным от дефектов. Два решения проблемы плохих блоков - одно на уровне аппаратуры другое на уровне ядра ОС.
Первый способ - хранить список плохих блоков в контроллере диска. Когда контроллер инициализируется, он читает плохие блоки и замещает дефектный блок резервным, помечая отображение в списке плохих блоков. Все реальные запросы будут идти к резервному блоку. Следует иметь в виду, что при этом механизм подъемника (наиболее распространенный механизм обработки запросов к блокам диска) будет работать неэффективно. Дело в том, что существует стратегия очередности обработки запросов к диску (подробнее см. главу ввод-вывод). Стратегия диктует направление движения считывающей головки диска к нужному цилиндру. Обычно резервные блоки размещаются на внешних цилиндрах. Если плохой блок расположен на внутреннем цилиндре, и контроллер осуществляет подстановку прозрачным образом, то кажущееся движение головки будет осуществляться к внутреннему цилиндру, а фактическое к внешнему. Это является нарушением стратегии и, следовательно, минусом данной схемы.
Решение на уровне ОС может быть следующим. Во-первых, необходимо тщательно сконструировать файл, содержащий плохие блоки. Тогда они изымаются из списка свободных блоков. Затем нужно сделать так, чтобы к этому файлу не было обращений. Если это возможно, то проблема решена.
12.9 Производительность файловой системы
Наиболее типичная техника повышения скорости работы с диском кэширование. Обращение к диску обычно в 100000 раз медленнее, чем к памяти. (Обращение к памяти - несколько сотен наносекунд, а чтение блока с диска - десятки миллисекунд). За счет кэширования дисковой информации в памяти можно сократить число дисковых операций, храня часть блоков диска, к которым перед этим производились обращения, в специальной области памяти, именуемой буферным кэшем (cache). Это оказывается возможным вследствие присущего ОС свойству локальности (о свойстве локальности много говорилось в главах, посвященных описанию работы системы управления памятью).
Различные алгоритмы используются для управления кэшем, но наиболее общий - при запросах на чтение проверять находится ли соответствующий блок в буфер кэша, и если нет, то вначале считать его в буфер.
Аккуратная реализация кэширования требует решения нескольких проблем.
Во-первых, емкость буфера кэша ограничена. Когда блок должен быть загружен в заполненный буфер кэша, возникает проблема замещения блоков, то есть отдельные блоки должны быть удалены из него. Эта ситуация очень напоминает ситуацию с выталкиванием страниц памяти, и здесь используются те же алгоритмы, например, FIFO, Second Chance и LRU. Разница лишь в том, что ссылки кэша не столь часты, как ссылки на страницы памяти.
Замещение блоков должно осуществляться с учетом их важности для файловой системы. Блоки должны быть разделены на категории, например: блоки индексных узлов, блоки косвенной адресации, блоки директорий, заполненные блоки данных и т.д., и в зависимости от принадлежности блока к той или иной категории применять к ним разную стратегию замещения.
Во-вторых, поскольку кэширование использует механизм отложенной записи, при котором модификация буфера не вызывает немедленной записи на диск, серьезной проблемой является старение информации в дисковых блоках, образы которых находятся в буферном кэше. Несвоевременная синхронизация буфера кэша и диска может привести к очень нежелательным ситуациям в случае отказов оборудования или программного обеспечения. Поэтому стратегия и порядок отображения информации из кэша на диск должна быть тщательно продумана.
Так, блоки существенные для совместимости файловой системы (блоки индексных узлов, блоки косвенной адресации, блоки директорий), должны быть переписаны на диск немедленно, независимо от того в какой части LRU цепочки они находятся. Необходимо тщательно выбрать порядок такого переписывания.
В UNIX имеется для этого вызов SYNC, который заставляет все модифицированные блоки записываться на диск немедленно. Для периодической синхронизации содержимого кэша и диска запускается фоновый процесс-демон, который делает это через определенный промежуток времени (например, каждые 30 сек.). Кроме того, можно организовать синхронный режим работы с отдельными файлами, задаваемый при открытии файла, когда все изменения в файле немедленно сохраняются на диске.
В ОС MS-DOS, в отличие от Unix, принято записывать каждый модифицированный блок на диск как можно скорее. Следствие такой стратегии - удаление дискеты из UNIX системы без осуществления вызова SYNC почти всегда ведет к потере данных, тогда как у MS-DOS здесь проблем не возникает (в UNIX предполагается, что все диски жесткие и не вынимаются)
Кэширование - не единственный способ увеличения производительности системы. Другая важная техника - сокращение количества движений считывающей головки диска, за счет разумной стратегии размещения информации. Например, массив индексных узлов в Unix стараются разместить на средних дорожках. Также имеет смысл размещать индексные узлы поблизости от блоков данных, на которые они ссылаются и т.д.
12.10 Реализация некоторых операций над файлами.
В предыдущей главе перечислены основные операции над файлами.
В данном разделе будет описан порядок работы
![]() некоторых системных вызовов для работы с файловой системой, следуя главным
образом [1], с учетом совокупности
введенных в данной главе понятий.
некоторых системных вызовов для работы с файловой системой, следуя главным
образом [1], с учетом совокупности
введенных в данной главе понятий.
12.10.1 Системные вызовы, работающие с символическим именем файла.
Системные вызовы, связывающие pathname с дескриптором файла
Это функции создания и открытия файла. Например, в ОС Unix
fd = creat(pathname,modes);
fd
= open(pathname,flags,modes);
![]()
Другие операции над файлами, такие как чтение, запись, позиционирование головок чтения-записи, воспроизведение дескриптора файла, установка параметров ввода-вывода, определение статуса файла и закрытие файла, используют значение полученного дескриптора файла.
Рассмотрим работу системного вызова open.
Логическая файловая подсистема просматривает файловую систему в поисках файла по его имени. Она проверяет права на открытие файла и выделяет открываемому файлу запись в таблице файлов. Запись таблицы файлов содержит указатель на индексный узел открытого файла. Ядро выделяет запись в личной (закрытой) таблице в адресном пространстве процесса, выделенном процессу (таблица эта называется таблицей пользовательских дескрипторов файлов), и запоминает указатель на эту запись. Указателем выступает дескриптор файла, возвращаемый пользователю. Запись в таблице пользовательских файлов указывает на запись в глобальной таблице файлов.

Рис. 12.12 Структуры данных после открытия файлов
Первые три пользовательских дескриптора (0, 1 и 2) именуются дескрипторами файлов: стандартного ввода, стандартного вывода и стандартного файла ошибок. Процессы в системе UNIX по договоренности используют дескриптор файла стандартного ввода при чтении вводимой информации, дескриптор файла стандартного вывода при записи выводимой информации и дескриптор стандартного файла ошибок для записи сообщений об ошибках.
Связывание файла
Системная функция link связывает файл с новым именем в структуре каталогов файловой системы, создавая для существующего индекса новую запись в каталоге. Синтаксис вызова функции link:
link(source file name, target file name);
где source file name - существующее имя файла, а target file name - новое (дополнительное) имя, присваиваемое файлу после выполнения функции link.
Сначала ОС, определяет местонахождение индекса исходного файла и увеличивает значение счетчика связей в индексном узле. Затем ядро ищет файл с новым именем; если он существует, функция link завершается неудачно и ядро восстанавливает прежнее значение счетчика связей, измененное ранее. В противном случае ядро находит в родительском каталоге свободную запись для файла с новым именем, записывает в нее новое имя и номер индекса исходного файла.
Удаление файла
В Unix системная функция unlink удаляет из каталога точку входа для файла. Синтаксис вызова функции unlink:
unlink(pathname);
Если удаляемое имя является последней связью файла с каким-либо каталогом, ядро в итоге освобождает все информационные блоки файла. Однако если у файла было несколько связей, он остается все еще доступным под другими именами.
Для того чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индексного узла, освобождая все блоки прямой адресации немедленно. Что касается блоков косвенной адресации, ядро освобождает все блоки, появляющиеся на различных уровнях косвенности, рекурсивно, причем в первую очередь освобождаются блоки с меньшим уровнем.
12.10.2 Системные вызовы, работающие с файловым дескриптором
Открытый файл может использоваться для чтения и записи последовательностей байтов. Для этого поддерживаются два системных вызова read и write, работающие с файловым дескриптором (или handle'ом в терминологии Microsoft), полученном при ранее выполненных системных вызовах open или creat.
Функции ввода-вывода из файла
Системный вызов read выполняет чтение обычного файла
number = read(fd,buffer,count);
где fd - дескриптор файла, возвращаемый функцией open, buffer - адрес структуры данных в пользовательском процессе, где будут размещаться считанные данные в случае успешного завершения выполнения функции read, count - количество байт, которые пользователю нужно прочитать, number - количество фактически прочитанных байт.
Синтаксис вызова системной функции write (писать):
number = write(fd,buffer,count);
где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индексного узла.
Обычное использование системных функций read и write обеспечивает последовательный доступ к файлу, однако процессы могут использовать вызов системной функции lseek для указания места в файле, где будет производиться ввод-вывод, и осуществления произвольного доступа к файлу. Синтаксис вызова системной функции:
position = lseek(fd,offset,reference);
где fd - дескриптор файла, идентифицирующий файл, offset - смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи.
12.11 Современные архитектуры файловых систем
Современные ОС предоставляют пользователю возможность работать сразу с несколькими файловыми системами (Linux работает с Ext2fs, FAT и др.). Файловая система в традиционном понимании становится частью более общей многоуровневой структуры (см. рис. 12.12).
На верхнем уровне, на котором располагается так называемый диспетчер файловых систем (например, в Windows 95 этот компонент называется installable filesystem manager). Он связывает запросы прикладной программы с конкретной файловой системой.
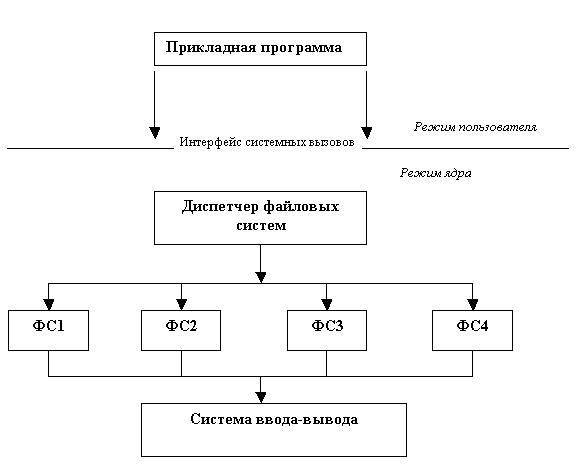
Рис. 12.13 Архитектура современной файловой системы
Каждая файловая система (иногда говорят драйвер файловой системы) на этапе инициализации регистрируется у диспетчера, сообщая ему точки входа, для последующих обращений к данной файловой системе.
Та же идея поддержки нескольких файловых систем в рамках одной ОС может быть реализована по-другому, например, исходя из концепции виртуальной файловой системы. Виртуальная файловая система (vfs) представляет собой независимый от реализации уровень и опирается на реальные файловые системы (s5fs, ufs, FAT, NFS, FFS, Ext2fs). При этом возникают структуры данных виртуальной файловой системы, типа виртуальных индексных узлов vnode, которые обобщают индексные узлы конкретных систем .
Реализация файловой системы связана с такими вопросами, как поддержка понятия логического блока диска, связывания имени файла и блоков его данных, проблемами разделения файлов и проблемами управления дискового пространства.
Наиболее распространенные способы выделения дискового пространства: непрерывное выделение, организация связного списка и система с индексными узлами.
Файловая система часто реализуется в виде слоеной модульной структуры. Нижние слои имеют дело с оборудованием, а верхние с символическими именами и логическими свойствами файлов.
Директории могут быть организованы различными способами и могут хранить атрибуты файла и адреса блоков файлов, а иногда для этого предназначается специальная структура (индексные узлы). Проблемы надежности и производительности файловой системы важнейшие аспекты ее дизайна.